Talking with AI: Optimal UX in ‘multiple-command’ tasks
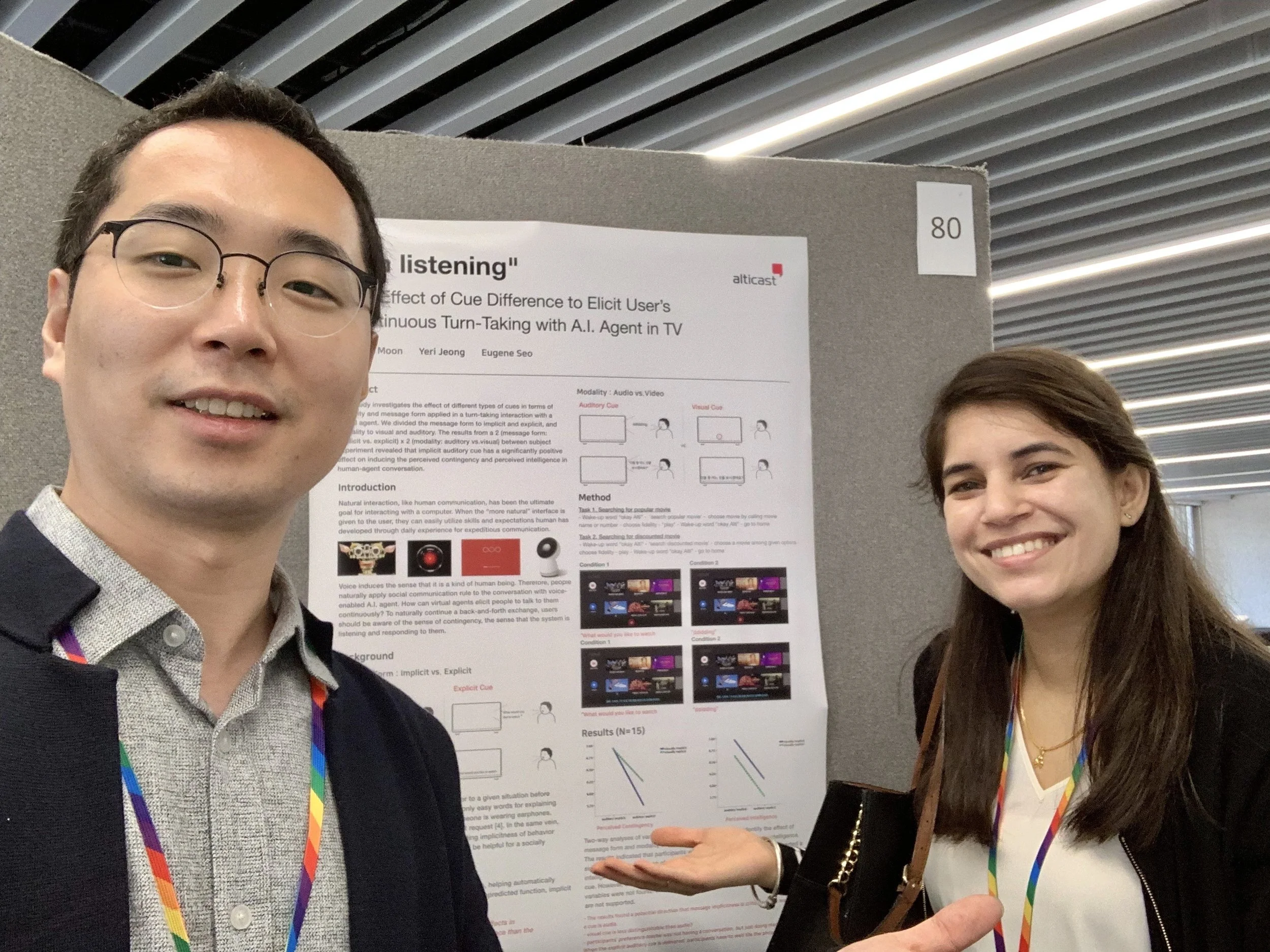
I’m listening: The Effect of Cue Difference to Elicit User’s Continuous Turn-Taking with A.I. Agent in TV
Presented at Ubicomp 2019 Poster session! Click to read the paper
Category
Experimental Research
* If you are looking for wireframe or visual UI skill, please take a look at other category works
Keywords
Conceptualization - Hypothesis - Experiment -Statistics - Leading research project
My role
as a 1st author,
- Found the problem in continuous turn-taking voice UX
- Envisioned and motivated colleagues to participate in and proceed with this research project.
- Re-defined the phenomenal problems to the conceptual variable
- Made hypotheses based on psychological references
- Lead colleague to make proper experiment material for the experiment
- Conducted between-subject experiment for 2 days with 15 participants
- Analyzed statistical results with SPSS (ANOVA)
After several rejections and revisions, this research finally got accepted to UBICOMP, a world-renowned HCI conference as a poster
Members
Yohan Moon, Yeri Jeong, Eugene Seo
Duration
2018.12 - 2019.04 (Published on 9th, Sep. 2019)
Introduction

Natural conversation is the ultimate goal of human-AI interaction. Many movies illustrating the future show a long and continuous conversation between a voice assistant and a user, and it can be possible and natural only when the person doesn’t have to say the ‘wake-up word’ whenever they say something.
So, providing a proper sense of ‘contingency’ is critical to avoid repetitive ‘wake-up words’ for multiple turn-takings. A sense of ‘contingency’ here means, the sense that the system is listening and responding to them, so users know when to talk next sentence.
The problem of using a voice interface in some tasks
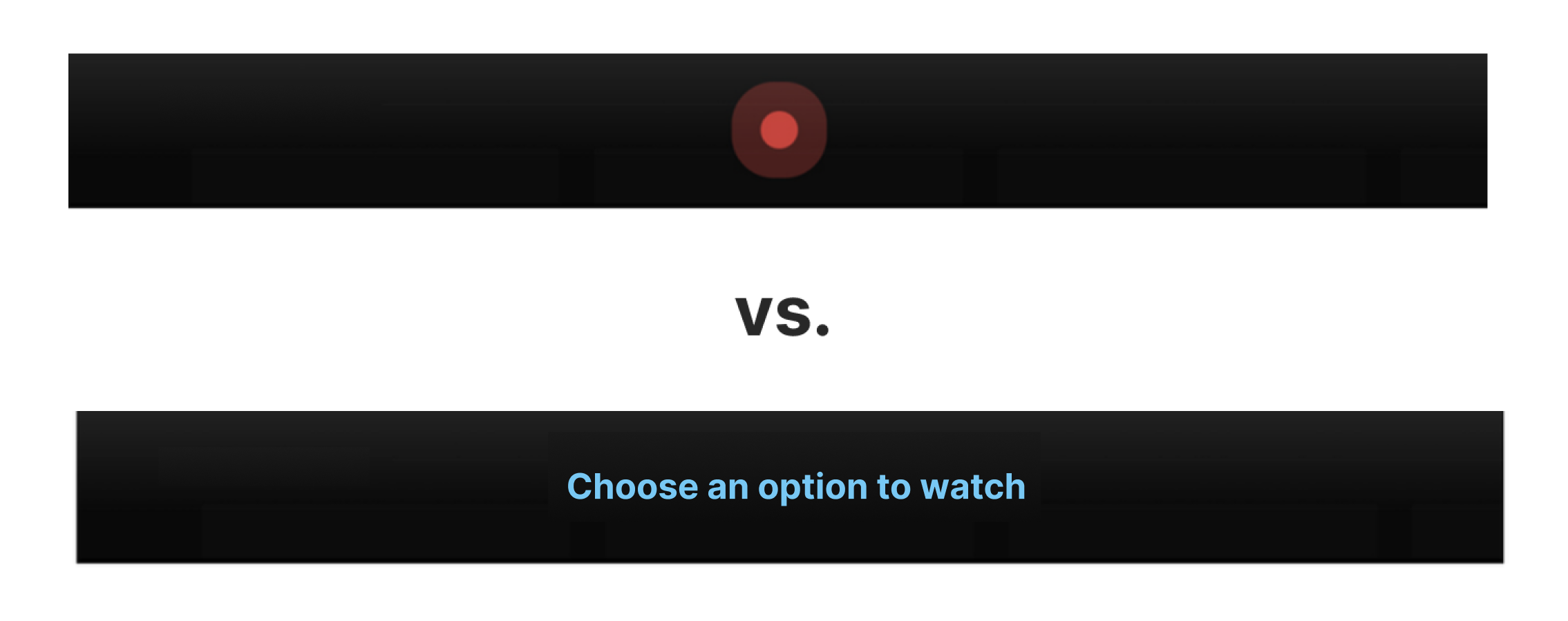
Some task such as playing a movie requires multiple steps so it becomes a ‘long’ and ‘continuous’ interaction.
Single-command task
: <Wake-up word, question, answer> Paradigm
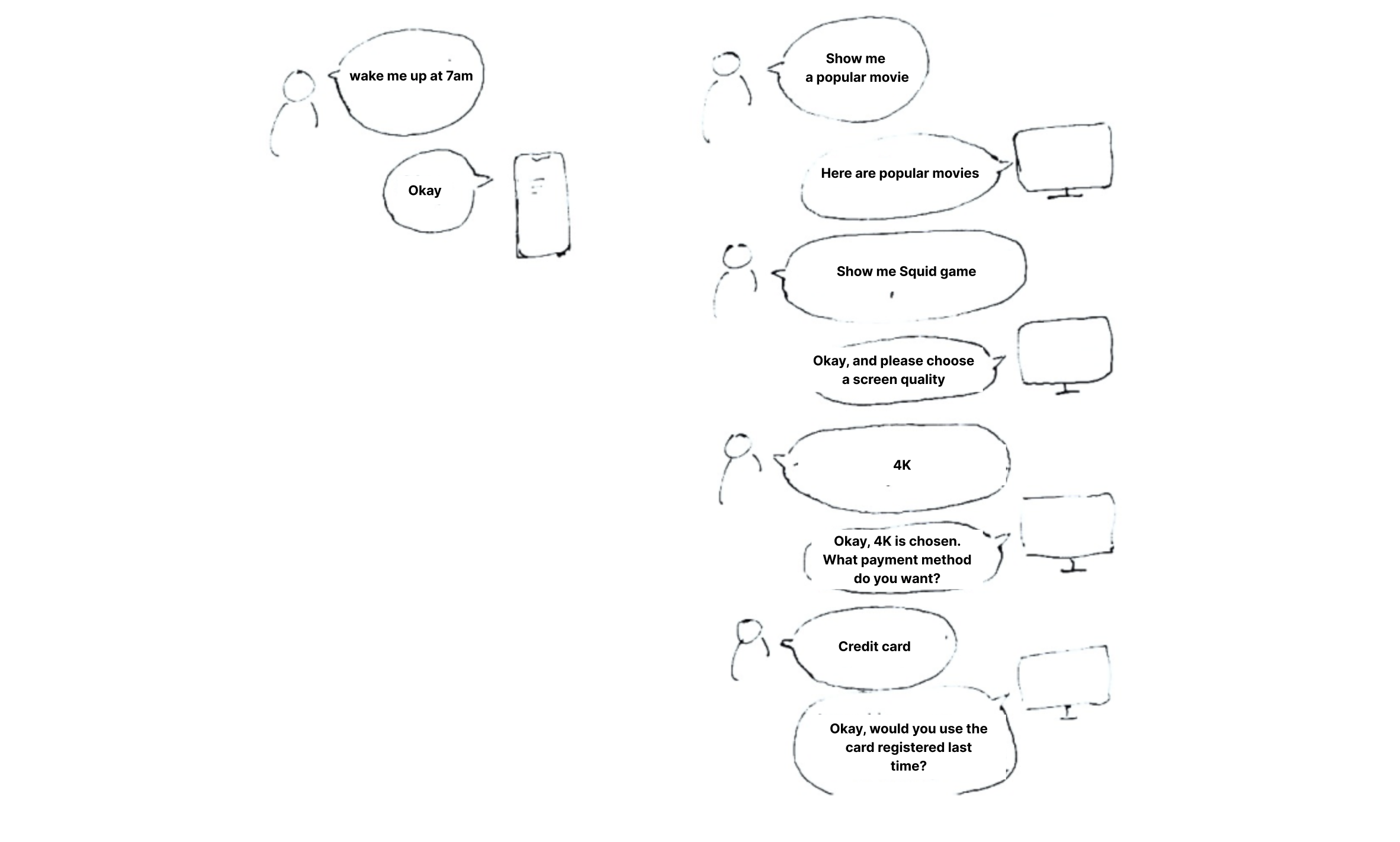
Normally we just use one single-sentence command such as, “Siri”(user) - ‘diding’(siri) - “wake me up at 6 am”(user"). Maybe this is already enough for simple daily tasks.
Multiple-command task
: Some specific tasks are not covered by one single <Wake-up word, question, answer>
But, still, some specific tasks require a bit longer conversation to complete the task fully. TV usage is one example.
Before users really fix what to watch, they keep searching. Changing channels… searching popular movies… checking the price (if it’s paid option)… choosing one option out of 3 or 4 choices... To make this task comfortably completed with voice, the user better know when to talk the next sentence after one command. To do this, users should not say ‘Wake-up word'‘ every time they command. So, nowadays there are voice assistants that keep their microphones turned on after one command, so the user can continuously give the next command. However…. to do that, users should clearly know that it’s their turn to speak. In other words, it’s important to give a sense of contingency to the user. Then, how can we give users a sense of contingency in continuous conversation? What designs can be there, and what design will deliver a stronger sense of contingency?
HCI history: Toward the natural interaction
People consistently have attempted to achieve more natural communication between humans and computers
Natural interaction, like human communication, has been the ultimate goal for interacting with a computer. When the “more natural” interface is given to the user, they can easily utilize the skills and expectations that humans have developed through daily experience for expeditious communication.

Contingency in Continuous Turn-Taking
A plethora of human-computer interaction (HCI) studies based on the Computers Are Social Actors (CASA) paradigm has constantly demonstrated that the social rules and expectations in human-human interactions can be applied to human-computer interaction.
One widespread expectation in human conversation is that the counterpart is listening as long as he stays near the person speaking, exchanging turns to talk to each other. Likewise, it is assumed that people would expect continuous turn-taking with A.I. agents, without saying the agent's name whenever they speak. But, if the user doesn’t call the A.I. name, we used to assume that the A.I. is not listening to the user.
Nowadays as technology and UX is getting developed, some voice-enabled devices are available for continuous turn-taking conversation, without calling their A.I. name. In that situation, what can be the best design to let user know A.I. is already listening even when they didn’t call A.I name?
Theoretical Background
Message form: Implicit vs. Explicit
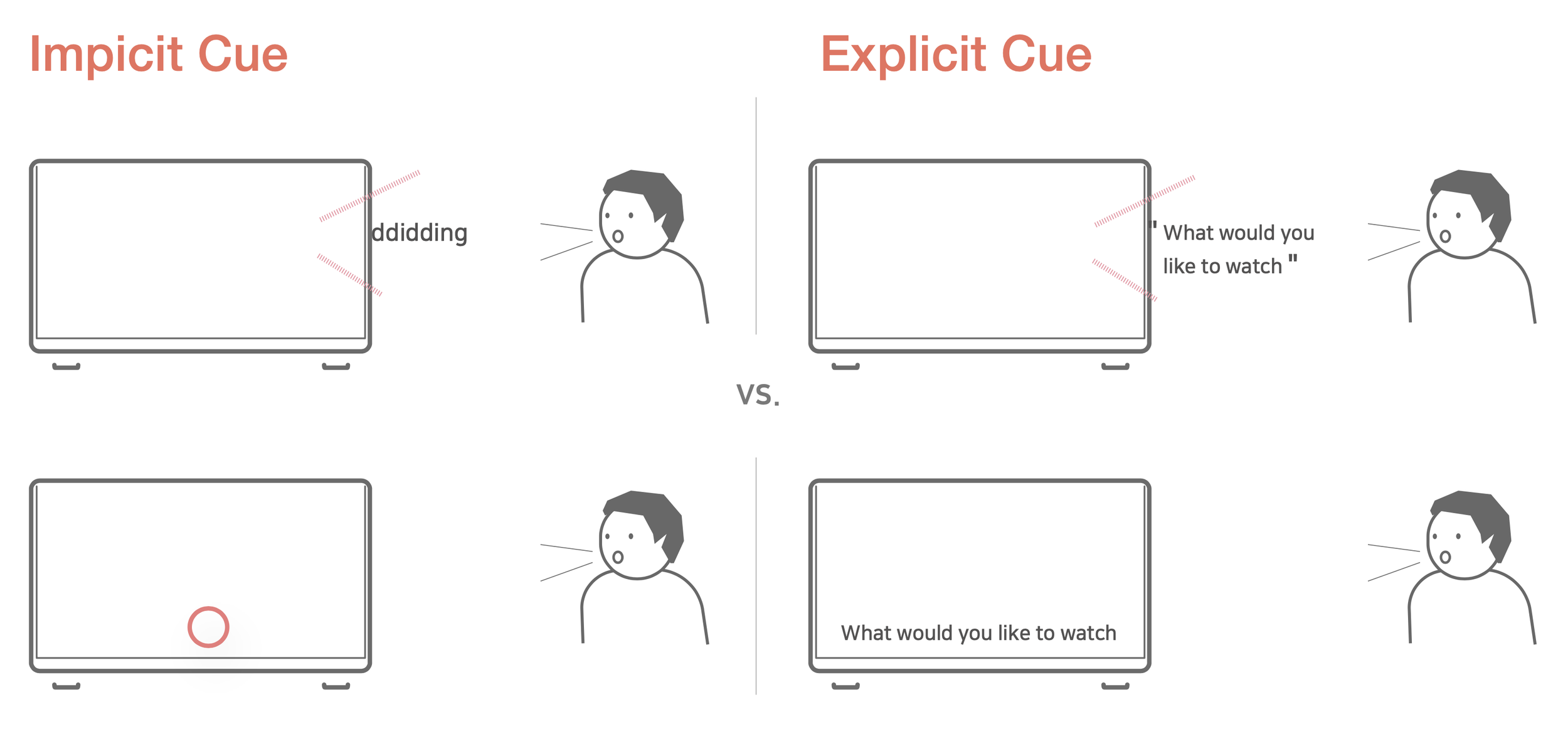
All People naturally adjust their behavior to a given situation before thinking about it. For example, we use only easy words for explaining things to kids and do not talk when someone is wearing earphones. These behaviors happen without explicit request [4]. In the same vein, like human-human interaction, the adjusting implicitness of behavior in conversation with a virtual agent would be helpful for a socially appropriate interaction
When Implicit interaction is appropriate?
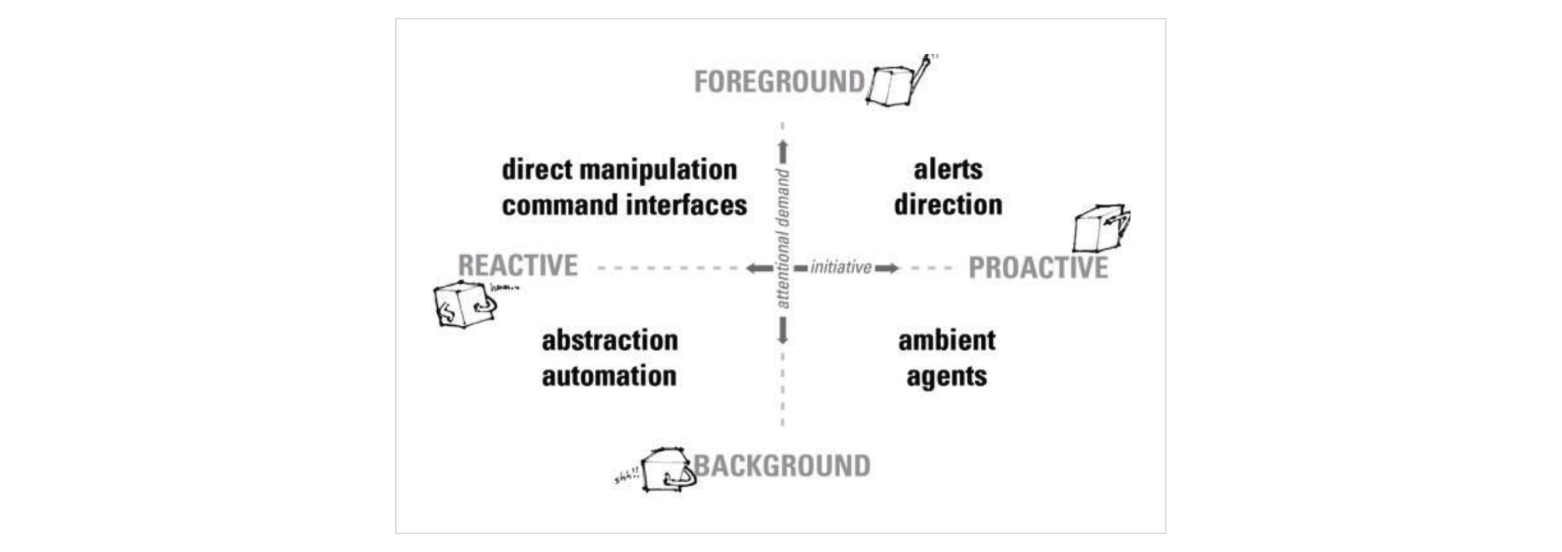
The implicit interaction framework by Wendy Ju and Larry Leifer(2008).
The Design of Implicit Interactions:Making Interactive SystemsLess Obnoxious. Design Issues: Volume 24, Number 3 Summer 2008
According to the previous research by Wendy Ju and Larry Leifer (2008), in case of giving an alert, guiding user actions, helping automatically execut background functions, and giving unpredicted function, implicit interaction would be appropriate.
Hypothesis 1: Implicit type of cue will have positive effects in inducing more sense of contingency and intelligence than the explicit type of cue
Modality: Visual vs. Audio
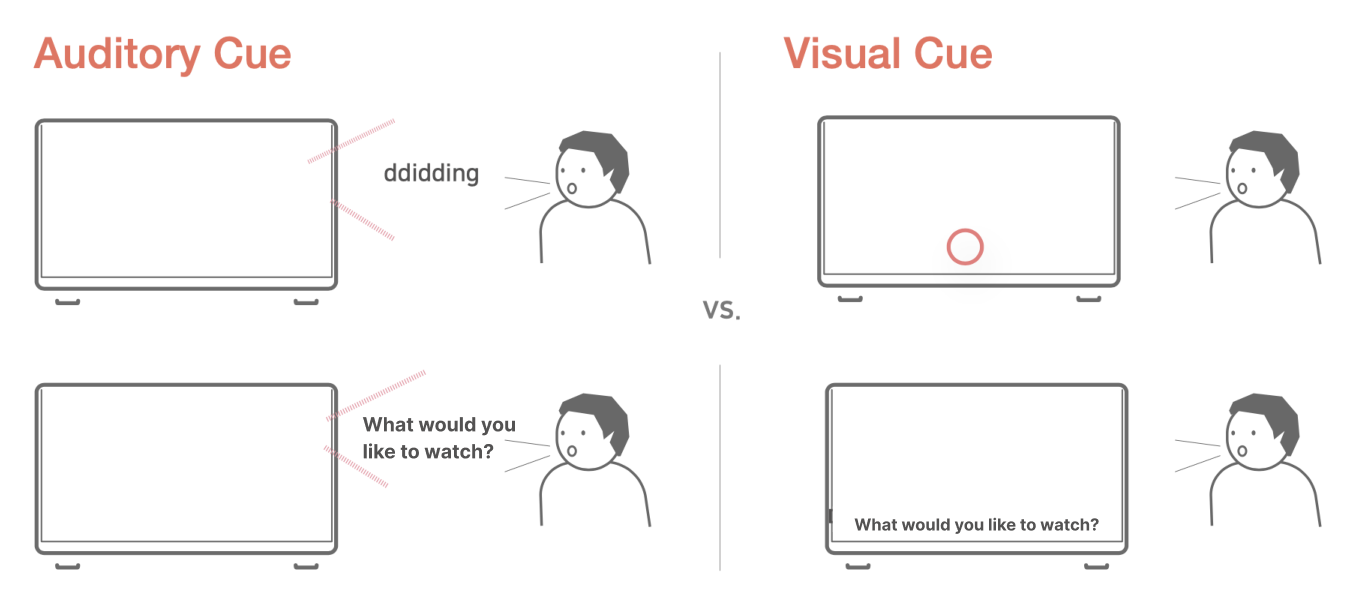
This study also differentiated modality as two parts: visual and audio. We assume that each modality has relative advantages. When the message is delivered visually to a user explicitly, the user can read the message and read it again in case it is too complicated to understand by listening only one time. This may be more convenient to the user. In this sense, direct visual modality would lead the user to a more positive response than when the message is not displayed on the screen. Thus, the next hypothesis is as follow:
Hypothesis 2: Visually explicit cue would have positive effects in inducing a stronger sense of contingency and intelligence of a virtual agent than visually implicit cue.
On the other hand, when the message is delivered through audio, the user either hears a simple sound, or a spoken language, a distinctive anthropomorphic cue. Because human has evolved the communication way by speaking to each other, hearing the spoken message is more similar to human communication than simple sound. Considering the natural interaction is more desirable and has a positive effect on human-computer interaction [1,10], the auditory explicit cue is more natural, similar to human conversation. Thus, the next hypothesis is inferred.
Hypothesis 3: Auditory explicit cue would show positive effects in inducing a stronger sense of contingency and intelligence of a virtual agent than auditory implicit cue.
Experiment method
We made a half-working prototype based on the experiment tasks. One person who manipulate the prototype was in the next room without notice to users. We conducted a between-subject experiment for 2 days with 15 participants.
Manipulation method
: Wizard of Oz (half-prototype)
Experiment type
: Between-subject
Tasks
: 'Searching for popular movie’, ‘Searching for discounted movie’
Participants
: 15 people (men 6, women 9)
We divided the message form to implicit and explicit, and modality to visual and auditory.

Visual condition: Implicit vs. Explicit
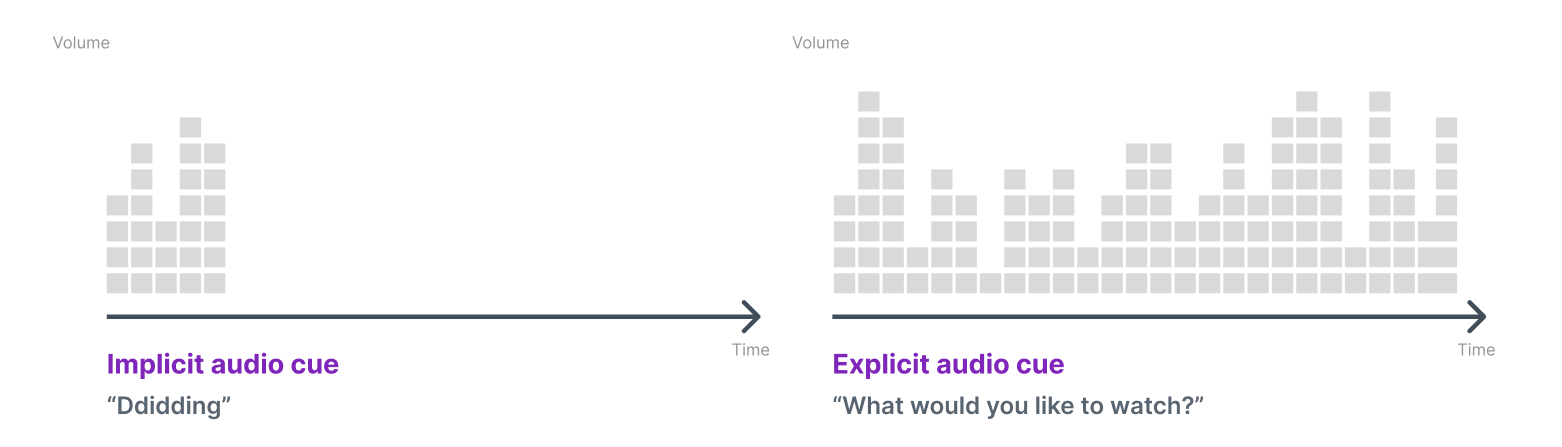
Audio condition: Implicit vs. Explicit
So the all conditions we have are those 4 conditions: 2 (message form: implicit vs. explicit) x 2 (modality: auditory vs. visual)
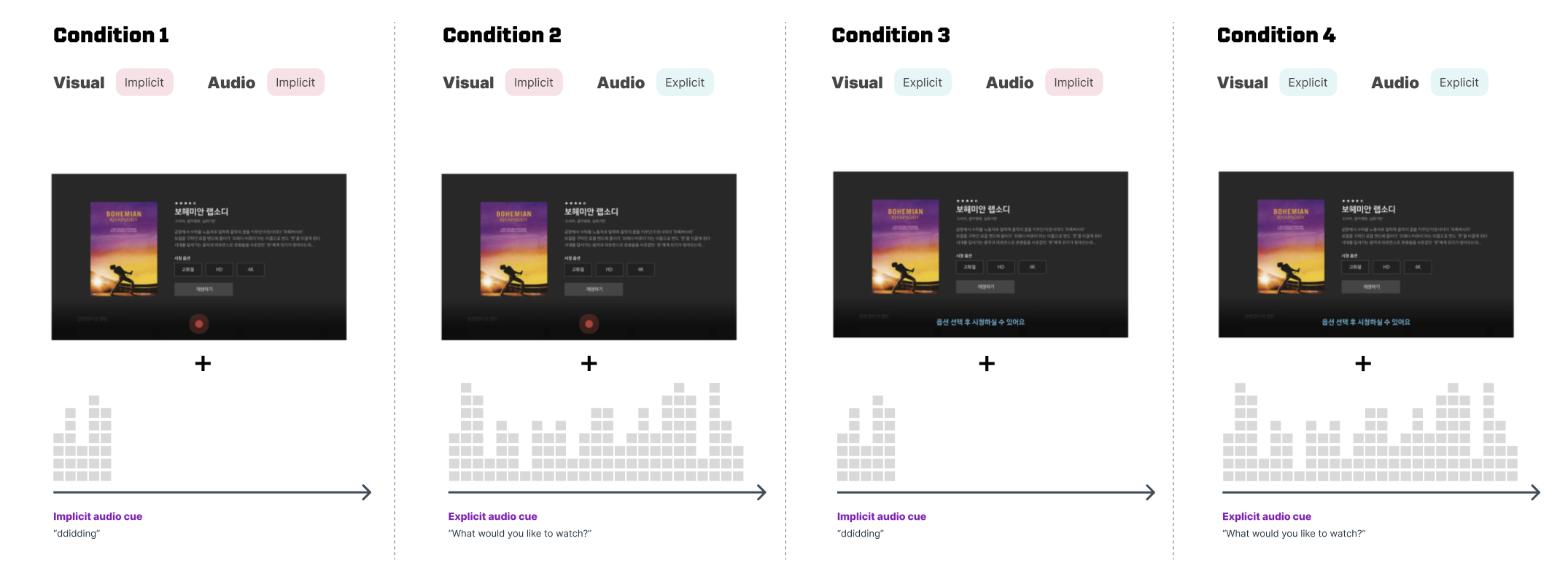
The 2 task flows which were guided to participants were as below:

Flow of each task
Result
Two-way analyses of variance (ANOVAs) were conducted to identify the effect of message form and modality on a sense of contingency and perceived intelligence. The results indicated that participants who were given implicit audio cue reported a significantly stronger sense of contingency, F (1, 11) = 5.35, p < .05, and perceived intelligence, F (1, 11)= 7.35, p < .05, than those who were given an explicit audio cue. However, the effect of modality and the interaction effect of two independent variables were not found. Therefore, while the H1 is partially supported, H2 and H3 are not supported.
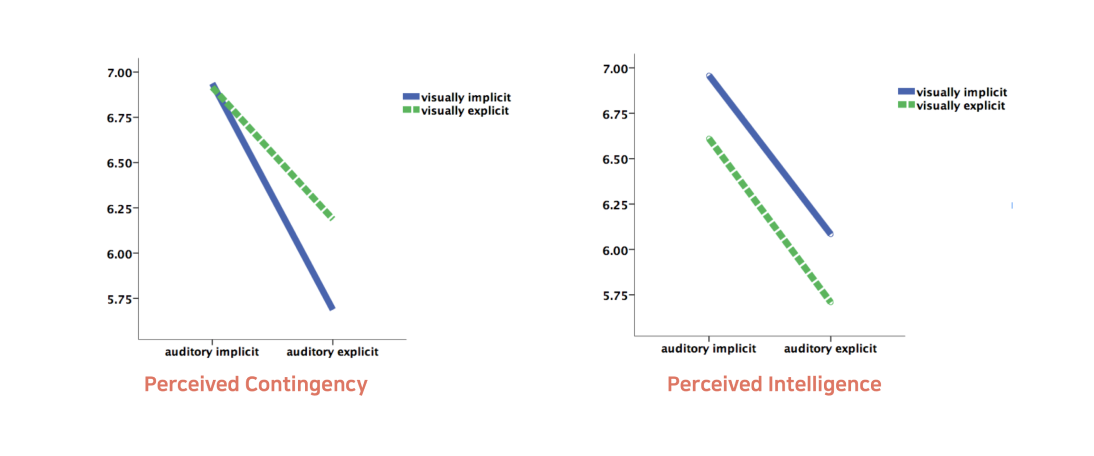
Conclusion

- When an audio cue is implicit, it delivers the strongest sense of contingency and intelligence of a voice assistant, regardless of visual cue.
- Participants’ preference maybe was not having a conversation, but just doing manipulation. When the explicit auditory cue is delivered, participants have to wait for till the phrase ends
Achievement
This research got accepted at UBICOMP 2019 as a poster!
And I went there as a presenter